
How are server issues (faults etc) monitored?
Automated heartbeat monitoring and health checks.


We have automated heart beat monitors which checks the health of the servers and a number of background tasks. In addition to checking the list of known tasks database read & write actions are performed and the available disk space is checked. If the heart beat monitor itself takes more than 5 minutes to run an alert is sent. The heart beat monitor runs every 15 minutes.
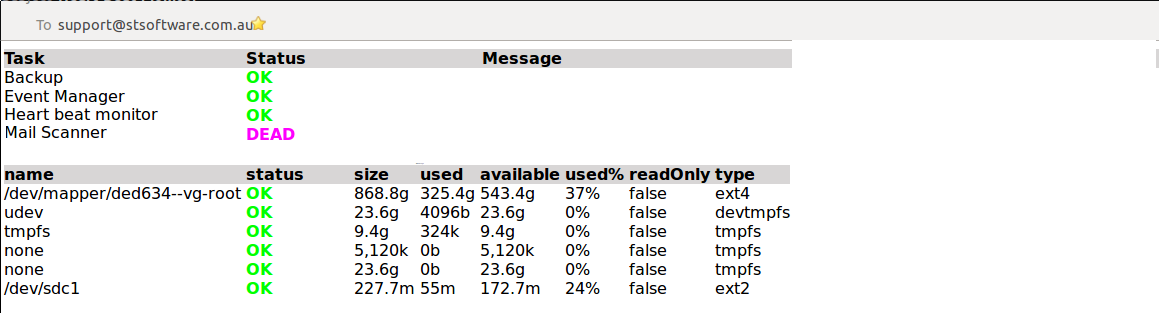
The list of tasks that the system will monitor are defined in the class DBTask.
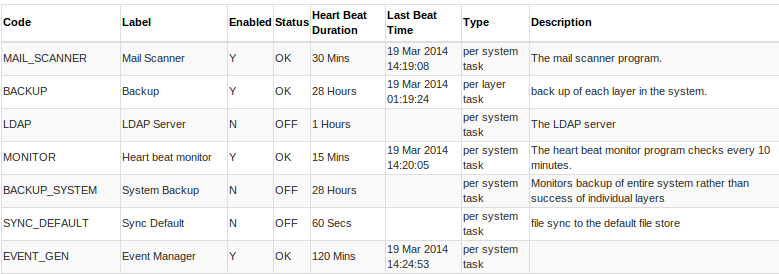
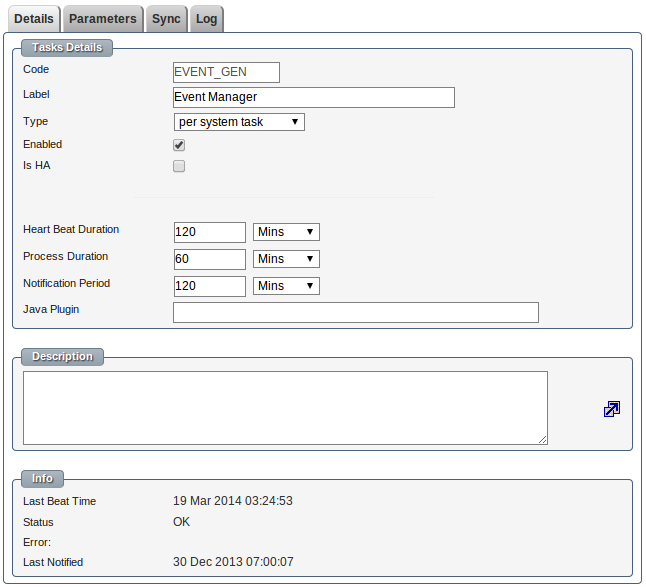
A task is defined by:-
- code which uniquely identifies this task
- The human readable label.
- Type of task
- One per system
- One per application/server
- One per database layer.
- If this task is enabled.
- HA (high availability) specifies that two or more machines will run the same task, if the the primary version of this task fails to update the heartbeat within the heart beat duration, the standby task runner will start automatically. If the first machine running the primary task responds after the standby task has started the primary will become the standby task.
- Heart beat duration is the time that a task must complete in, if the task takes longer than this period it's declared dead ( standby runner will start if in HA mode)
- Process duration is how long one run of this task is expected to task.
- Notification period is how frequently to notify that this process is dead or has an error.
Each server has it's own set of logs including:-
- Web Access logs
- SQL logs
- Message Queue logs
- sent
- received
- Server logs
All the logging is configured via log4j
Email alerts for serious errors are sent automatically via a Log4J delayed SMTP append-er which will batch errors into one email if more than one per minute was to be generated.